tag(1): del.icio.us-style file tagging
I’ve been using the social bookmarking service, del.icio.us, for a while now, and have watched similar tagging features move from site to site as a flexible way to lightly categorize various resources: bookmarks, blog posting, photos, etc. It’s therefore a little strange that no one has written a simple utility to give you similar category construction capabilities on your typical Unix-like file system. In this post, I propose a simple, portable design, contrast my design choices against some other possibilities, and then provide an initial implementation of that design in Perl.
Tagging
If you’ve not used del.icio.us, Technorati’s tag system, or any of the Web tagging systems, then a brief introduction is worthwhile. If you’re already familiar with tagging, then this section will alert you to my personal terminology around tagging operations and the resulting metadata.
By tagging, we mean the association of one or more keywords, called tags, with an entity. The tag set is the set of tags associated with the entity, which for the purposes of this post, is always a file.
Once you’ve accumulated a set of tagged files, the next step is to examine sets of files with common tags: each such set is a query. The link set is the set of all possible queries against the set of tags. That is, the set of files tagged with the same set of tags is a member of the link set. A particular member of the link set can be calculated dynamically, or the entirety of the set can be calculated in advance.
Querying tags
del.icio.us appears to calculate the per-tag queries on the fly, which is acceptable as the primary interface is the web page presented to the reader. (Caching is probably involved.) We instead have a choice: we can use our command, tag(1), or we can use the filesystem itself. Our choice is accompanied by a tradeoff between time (to compute queries) and space (inodes consumed). Although, as we will see, the space consumption is significant, the filesystem approach presents an easy interface for exploration.
By default, the link set is constructed in $HOME/tag:
$ ls ~/tag/
code/ doc/ linux/ rm/ thread/ utility/
conference/ greenline/ note/ solaris/ umem/
If we look in ~/tag/code, we see
$ ls ~/tag/code/
gumemd.pl@ pause.c@ tag.pl@ tagging/ umem/ utility/
symbolic links to files with that tag, and directories representing additional tags. This directory hierarchy is the link set: all possible queries are precalculated:
$ ls ~/tag/code/umem/
gumemd.pl@
If we go to the original file, tag(1) will tell us the tags on the file:
$ tag gumemd.pl
code umem
We can also query using the tag command, but it is merely walking the directory structure we constructed.
$ tag -q code
/home/sch/old-home/gumemd.pl
/home/sch/old-home/pause.c
/home/sch/play/tag/tag.pl
(This operation is relatively fast, as we would expect:
$ time tag -q code
/home/sch/old-home/gumemd.pl
/home/sch/old-home/pause.c
/home/sch/play/tag/tag.pl
real 0m0.068s
user 0m0.057s
sys 0m0.009s
Timing run performed on a 1.8 GHz Athlon64 running Solaris 10 and Perl 5.8.4.)
Adding tags is simple:
$ tag -a perl gumemd.pl
$ tag gumemd.pl
code umem perl
$ ls ~/tag/perl
code/ gumemd.pl@ umem/
As is deleting them:
$ tag -d perl gumemd.pl
$ ls ~/tag/perl
/home/sch/tag/perl: No such file or directory
So we have a design for basic tagging of files.
Tags and file system metadata consumption
It’s worth noting that precalculating the entire link set and storing it in a file system consumes file system metadata combinatorically, but that this consumption is capped by the (typical) limit on path length. Generally, we make M symbolic links for the n distinct tags on a single file, with M given by
$$ M(n) = \sum_{r = 1}^{n} \frac{n!}{(n – r)!} $$
That’s 325 links for 5 tags, plus as many directories again, for a total of 650 metadata units. On file systems that preallocate a fixed size pool of inodes, this kind of feature could lead to metadata exhaustion.
Tagging and file system operations
The key file system operation in our tagging system is renaming: how do we update the link and tag sets when a particular file is relocated within the filesystem? Deletion is a subset of this case; copying can be treated similarly to a set of tag-add operations on a previously untagged file.
If we just use mv(1), and have the link set and tag set stored externally to the file, then we end up with a depressing result:

The link set points to and the tag set is associated with the old location, and operations on these objects will fail. The file in its new location has lost all of its tags-derived metadata, and so has dropped out of our tagspace.
On some Unix-like OSes, certain filesystems support file attributes, such as Solaris’s UFS and Linux’s ext3fs. With attributes, data associated with the file is associated with the file in such a way that filesystem operations leave the association invariant (unless they involve the attribute data specifically). This modifies our operation to something more acceptable:
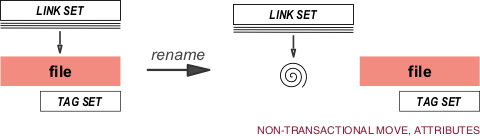
Although the link set is now stale, and we would have to rebuild the entire link set to remove the stale links to the old location, and to generate the correct links to the new one.
It is clear that what we want to occur is simultaneous updating of the link and tag sets with each operation: we want transactional operations.

One way to achieve a transactional operation is to get beneath the rename(2) system call, and to update both the link set and the tag set within an underlying tagging file system. It would be straightforward to implement a translucent file system that offered a namespace for the link set, and used an underlying on-disk filesystem to store the appropriate data. But, like our declining to use attributes earlier, we pass on an in-kernel implementation because of the associated portability costs. Instead, we have to encapsulate the various steps into an apparent transaction, by offering rename and remove operations in the command itself.
We implement encapsulated operations in the prototype version by wrapping the standard Unix-like commands: cp(1), mv(1), and rm(1). The syntax is
$ tag --mv srcfile dstfile
and similarly for the other commands.
Implementation
As I noted earlier, the code is a draft implementation and is grossly undertested. There are numerous improvements that could be made to the implementation—the tying and untying for multiple tag operations is an obvious performance sink. Architecturally, the script should be separated into a module providing tagging functionality and a command that presents the module’s functionality as an elegant command line interface. (It would be a reasonable position to move tagging into a small C library, such that a simple common tagging infrastructure could be made available. We could alternatively commit to a specific DBM file format and offer access from multiple symbolic link-capable languages.)
Implementation improvements would include: recognizing when an operation (tag retrievals in particular) is on an in-the-link-set symbolic link, resynchronizing/repairing databases and link hierarchies, better documentation (although the script does embed minimal documentation using POD), a test suite, and use of ExtUtils::MakeMaker or Module::Installer.
As always, I’m interested in your comments, suggestions, and references to similar work.
[T: Solaris ]